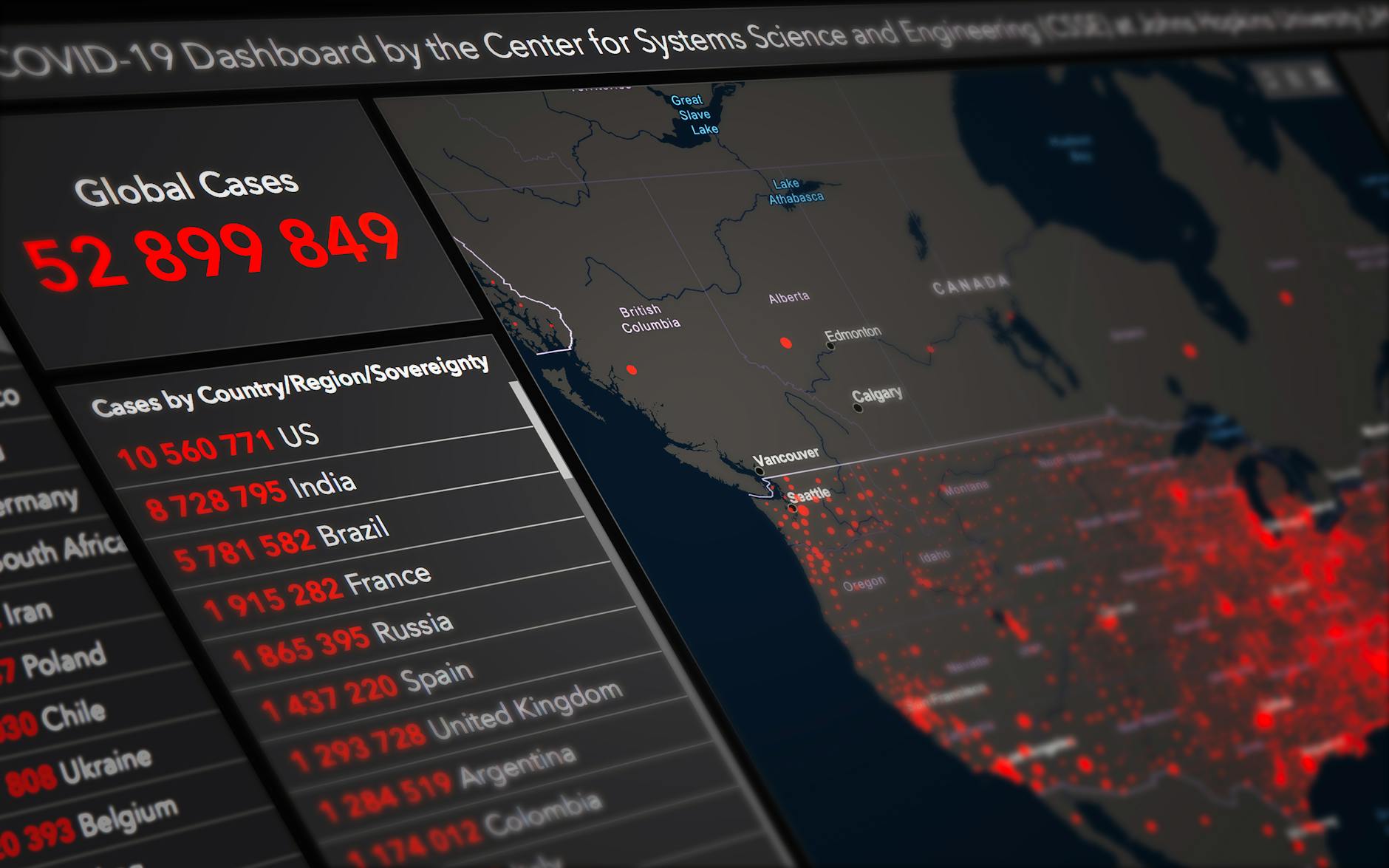
Šiuolaikinio verslo pasaulyje skaičiai kalba garsiau už žodžius. Elektroninės parduotuvės savininkai kasdien susiduria su gausybe duomenų, tačiau ne visi supranta, kaip šie skaičiai gali tapti tikru aukso kasykla. Konversijos statistika – tai ne vien tik procentai ir grafikai, bet gyva verslo širdis, kuri atskleidžia, kodėl vieni lankytojai tampa ištikimais pirkėjais, o kiti išnyksta kaip rūkas.
Kiekvienas paspaudimas, kiekvienas puslapio peržiūrėjimas, kiekvienas apleistas krepšelis pasakoja istoriją. Šios istorijos, tinkamai išanalizuotos, atskleidžia ne tik tai, kas vyksta dabar, bet ir tai, kas galėtų vykti ateityje, jei tik mokėtume klausytis to, ką mums sako duomenys.
Pardavimų piltuvo anatomija: kur slypi didžiausios galimybės
Pardavimų piltuvą galima palyginti su senovės amfiteatru – kiekvienas lygis turi savo paskirtį, ir kiekviename etape dalis žmonių išeina. Tačiau skirtingai nuo teatro, čia mes galime keisti scenarijų realiu laiku.
Pirmasis piltuvo lygis – suvokimas. Čia potencialūs pirkėjai pirmą kartą susipažįsta su jūsų prekės ženklu. Statistika rodo, kad vidutiniškai tik 2-3 procentai pirmojo apsilankymo metu įvyksta pirkimas. Tai reiškia, kad 97-98 procentai jūsų lankytojų išeina nepirkę nieko. Ar tai blogai? Ne būtinai. Svarbiausia suprasti, kodėl jie išeina ir kaip juos sugrąžinti.
Antrasis lygis – susidomėjimas. Čia lankytojai pradeda tyrinėti jūsų produktus, skaityti aprašymus, žiūrėti nuotraukas. Konversijos statistika šiame etape atskleidžia, kurie produktai sulaukia daugiausiai dėmesio, bet nesulaukia pirkimų. Tai – aukso gysla optimizavimui.
Trečiasis lygis – apsisprendimas. Produktai pridedami į krepšelį, bet pirkimas dar neįvyksta. Čia statistika dažnai atskleidžia skausmingą tiesą: vidutiniškai 70 procentų krepšelių lieka apleisti. Tačiau šie duomenys – ne nuosprendis, o kvietimas veikti.
Duomenų kalba: kaip iššifruoti klientų elgesio kodus
Kiekvienas klientas palieka skaitmeninį pėdsaką, tarsi detektyvo romano personažas. Šie pėdsakai formuoja unikalų elgesio modelį, kurį galima analizuoti ir interpretuoti.
Puslapių peržiūrų trukmė atskleidžia daugiau nei galėtumėte pagalvoti. Jei lankytojai produkto puslapyje praleidžia mažiau nei 30 sekundžių, tai gali reikšti, kad produkto aprašymas neįtikinantis arba nuotraukos nekokybės. Priešingai, jei jie praleidžia per daug laiko – galbūt informacijos per daug arba ji pateikta neaiškiai.
Atšokimo rodiklis (bounce rate) veikia kaip verslo termometras. Aukštas atšokimo rodiklis gali signalizuoti apie puslapio lėtą įkėlimo greitį, netinkamą dizainą mobiliesiems įrenginiams arba neatitikimą tarp reklamos žinutės ir realaus turinio.
Konversijos kelias (conversion path) atskleidžia, kokius puslapius lankytojai aplanko prieš pirkdami. Šie duomenys padeda suprasti, kurie turinio elementai yra svarbiausi sprendimo priėmimo procese. Galbūt pastebėsite, kad daugelis pirkėjų prieš pirkimą aplanko atsiliepimų skiltį – tai signalas stiprinti šį elementą.
Krepšelio apleistų galimybių fenomenas
Apleisti krepšeliai – tai šiuolaikinės e-prekybos Bermudų trikampis. Produktai dingsta iš krepšelių dažniau nei kojinės iš skalbimo mašinos. Tačiau skirtingai nuo kojinių, šiuos „dingusius” produktus galima susigrąžinti.
Statistikos analizė atskleidžia keletą pagrindinių apleistų krepšelių priežasčių. Netikėti papildomi mokesčiai pirkimo proceso pabaigoje veikia kaip šalta duš – 60 procentų pirkėjų atsisako pirkimo būtent dėl šios priežasties. Sprendimas paprastas: būkite skaidrūs dėl visų mokesčių nuo pat pradžių.
Sudėtingas registracijos procesas – kita dažna problema. Jei pirkimui reikia užpildyti daugiau nei 5-6 laukus, tikimybė, kad klientas atsisakys, išauga eksponentiškai. Svarstykit galimybę pirkti kaip svečias arba naudoti socialinių tinklų prisijungimą.
Mokėjimo metodų trūkumas taip pat gali tapti barjeru. Šiuolaikiniai pirkėjai tikisi rasti savo mėgstamą mokėjimo būdą – ar tai būtų PayPal, Apple Pay, ar net kriptovaliutos. Kuo daugiau galimybių suteiksite, tuo mažiau krepšelių liks apleista.
Mobiliosios prekybos revoliucija statistikos veidrodyje
Mobiliųjų įrenginių era iš esmės pakeitė e-prekybos žaidimo taisykles. Šiandien daugiau nei 50 procentų visų internetinių pirkimų atliekama mobiliaisiais įrenginiais, tačiau konversijos rodikliai mobiliosiose platformose vis dar atsilieka nuo kompiuterių.
Statistika atskleidžia įdomų paradoksą: nors mobiliaisiais įrenginiais naršoma daugiau, bet perkama mažiau. Vidutiniškai mobiliosios konversijos rodiklis yra 1,5-2 kartus mažesnis nei kompiuterių. Tai ne mobiliųjų įrenginių kaltė – tai dizaino ir naudotojo patirties iššūkis.
Mobiliosios optimizacijos svarbą pabrėžia ir puslapių įkėlimo greičio statistika. Jei mobilusis puslapis įsikrauna ilgiau nei 3 sekundes, 53 procentai lankytojų jį paliks. Kiekviena papildoma sekundė sumažina konversijos tikimybę 7 procentais.
Lietuvos rinkoje mobiliosios prekybos augimas yra ypač ryškus. Per pastaruosius trejus metus mobilieji pirkimai išaugo 150 procentų, o vidutinė pirkimo suma mobiliaisiais įrenginiais priartėjo prie kompiuterių rodiklių.
Sezoninių svyravimų ir trendų dešifravimas
E-prekybos pasaulis gyvena pagal savo unikalų kalendorių, kur kiekvienas mėnuo, savaitė, net dienos valanda turi savo charakterį. Statistikos analizė atskleidžia šiuos ritmus ir padeda juos panaudoti verslo naudai.
Lietuvos e-prekybos statistika rodo aiškius sezoninių svyravimų modelius. Lapkričio-gruodžio mėnesiais konversijos rodikliai vidutiniškai išauga 40-60 procentų, tačiau kartu išauga ir konkurencija. Išmanus verslo savininkas šiuos duomenis naudoja ne tik ruošdamasis aukštajam sezonui, bet ir ieškodamas galimybių „tylesniais” mėnesiais.
Savaitės dienų statistika atskleidžia dar vieną įdomų modelį. Antradieniai ir trečiadieniai dažnai būna produktyviausi B2B segmente, o penktadienio vakarai ir savaitgaliai – B2C. Šie duomenys padeda optimizuoti reklamos kampanijų laiką ir biudžeto paskirstymą.
Dienos valandų analizė gali atskleisti netikėtų galimybių. Pavyzdžiui, 22-24 valandų laikotarpis dažnai būna labai produktyvus impulsinių pirkimų kategorijai, o 10-12 valandos – apgalvotiems pirkimams.
Personalizacijos galios atskleidimas per duomenis
Šiuolaikinė e-prekyba juda link vis didesnio personalizavimo. Kiekvienas klientas nori jaustis ypatingas, ir statistika padeda tai pasiekti ne intuityviai, o remiantis konkrečiais duomenimis.
Klientų segmentavimas pagal elgesio modelius atskleidžia stulbinančias galimybės. Pavyzdžiui, klientai, kurie pirko produktą po to, kai peržiūrėjo atsiliepimus, yra 3 kartus labiau linkę pirkti vėl nei tie, kurie pirko iš karto. Šie duomenys padeda kurti tikslingas rinkodaros kampanijas.
Rekomendacijų sistemų efektyvumas taip pat matuojamas statistikos. Tinkamai sukonfigūruotos rekomendacijos gali padidinti vidutinę pirkimo sumą 10-30 procentų. Svarbiausia – analizuoti, kurios rekomendacijos veikia, o kurios tik erzina klientus.
El. pašto rinkodaros statistika atskleidžia personalizacijos galią. Personalizuoti el. laiškai generuoja 6 kartus didesnį konversijos rodiklį nei standartiniai. Tačiau personalizacija – tai ne tik kliento vardo įrašymas į temą, bet ir turinio pritaikymas pagal ankstesnį elgesį.
Ateities vizija: kai duomenys formuoja strategiją
Statistikos analizė – tai ne tik praeities ir dabarties supratimas, bet ir ateities formavimas. Išmokę skaityti duomenų kalbą, galite ne tik reaguoti į pokyčius, bet ir juos numatyti.
Konversijos optimizavimas niekada nesibaigia. Tai nuolatinis procesas, kuriame kiekvienas pakeitimas turi būti išmatuotas ir įvertintas. A/B testavimas tampa ne tik įrankiu, bet filosofija – viskas turi būti patikrinta praktiškai, o ne priimta kaip aksioma.
Dirbtinio intelekto ir mašininio mokymosi integravimas į statistikos analizę atskleidžia naujas galimybes. Algoritmai gali pastebėti modelius, kurių žmogus niekada nepastebėtų, ir pasiūlyti optimizavimo sprendimus realiu laiku.
Duomenų kokybė tampa vis svarbesnė nei kiekybė. Geriau turėti mažiau, bet tikslesnių duomenų, nei skęsti informacijos vandenyse. Svarbu ne tik rinkti statistiką, bet ir mokėti ją interpretuoti bei pritaikyti praktikoje.
Galiausiai, statistika – tai tik įrankis. Tikroji vertė atsiskleidžia tada, kai šie duomenys transformuojami į konkrečius veiksmus, kurie pagerina klientų patirtį ir didina verslo pelningumą. Kiekvienas procentas, kiekvienas rodiklis turi tapti žingsniu link geresnės, efektyvesnės ir pelningesnės elektroninės parduotuvės.